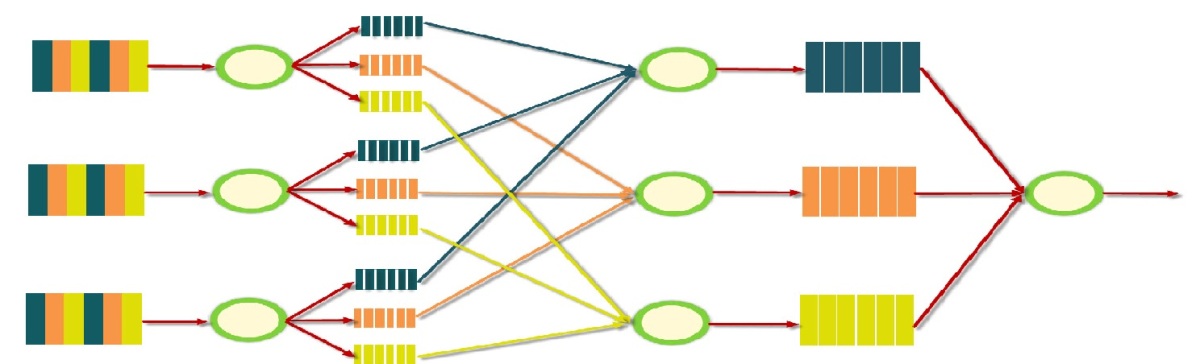
Java is an object oriented programming language, a programming environment, an operating environment (java virtual machine) and also a language for the web (JavaScript). There are few terms that we should understand to gain an insight as to how java works.
Java is an object oriented programming language, a programming environment, an operating environment (java virtual machine) and also a language for the web (JavaScript). There are few terms that we should understand to gain an insight as to how java works.
Emulator
Emulating means imitating. Similarly in computing emulating refers to a particular computer system (host) behaving like another computer system (guest). Emulators are the particular hardware that enables this imitation. By emulating older programming codes we can get better quality results (like quality graphics for games and stuff) for original programs. Continue reading “Facts about compiling a java application”